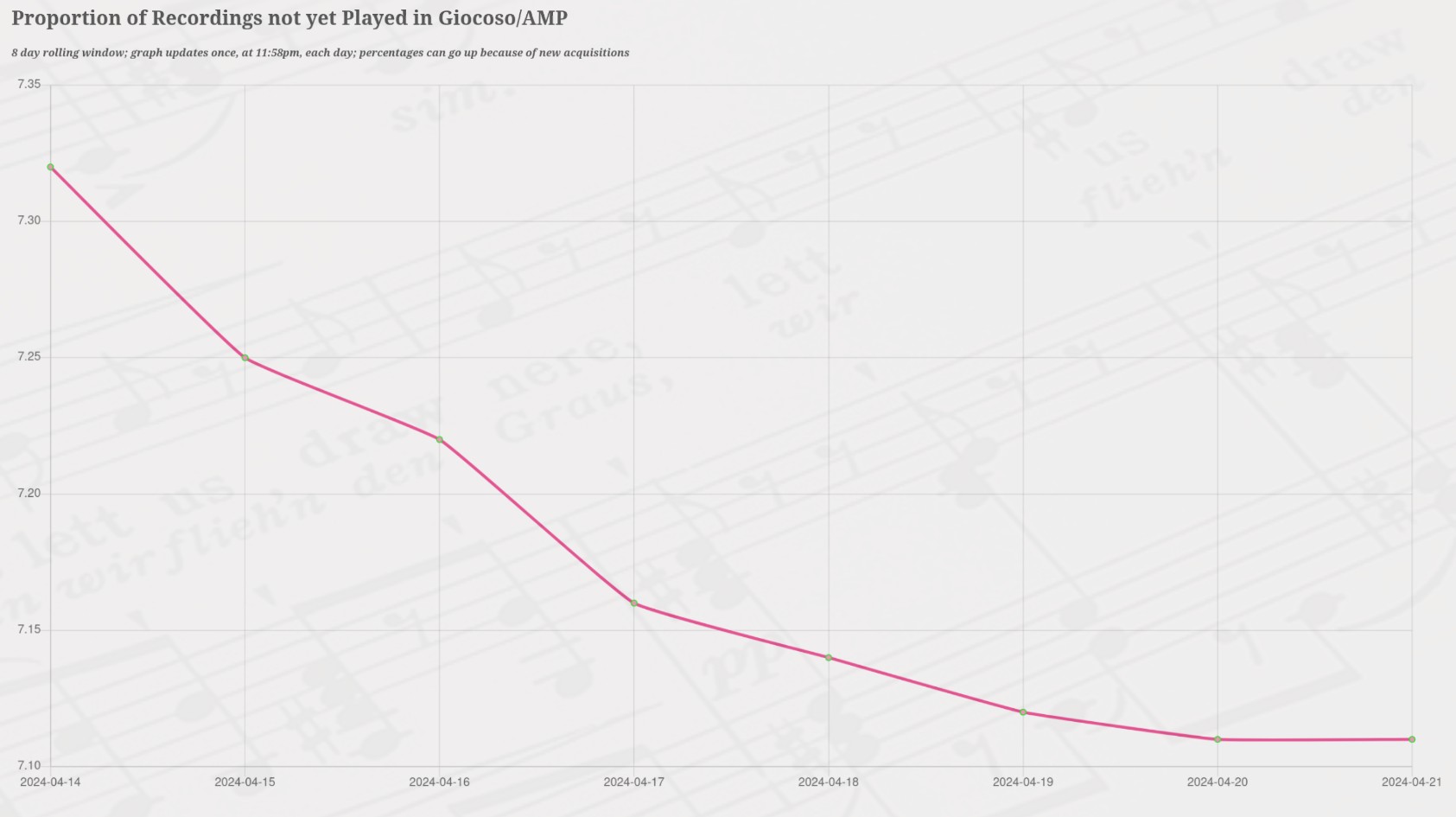
Giocoso Version 3.06 Released

A new release of Giocoso has been made available, fixing a recently-discovered minor, but annoying, bug. This brings the current version of Giocoso up to 3.06.
The bug was that if you used any of the non-default methods of selecting music to play from the Play Music menu (such as Option 2, where you specify filters to control the selection, or Option 5, where a playlist is used to determine what to play and in what order), the number of 'selections' to be played would be remembered if you halted those non-default plays early and then switched to using Option 1's 'play music with defaults' menu option. For example: take Option 2 and say 'play only music that lasts less than 10 minutes': maybe that will generate a list of things to be played that numbers 1345. After playing 4 things from that list, you interrupt the play (by issuing an Autostop request, for example) but do not quit Giocoso. Then you take Play Music option 1: the default, randomised selection of music now takes place... but Giocoso will still declare that there are 1345 items to be played (the top right-hand corner will display something like 'Selection 1 of 1345'). That's because it's a bug of omission: the default play method didn't explicitly set the limit on plays, so if another play option did, the default play method was stuck using that number of selections. [...]