Reaching the limits
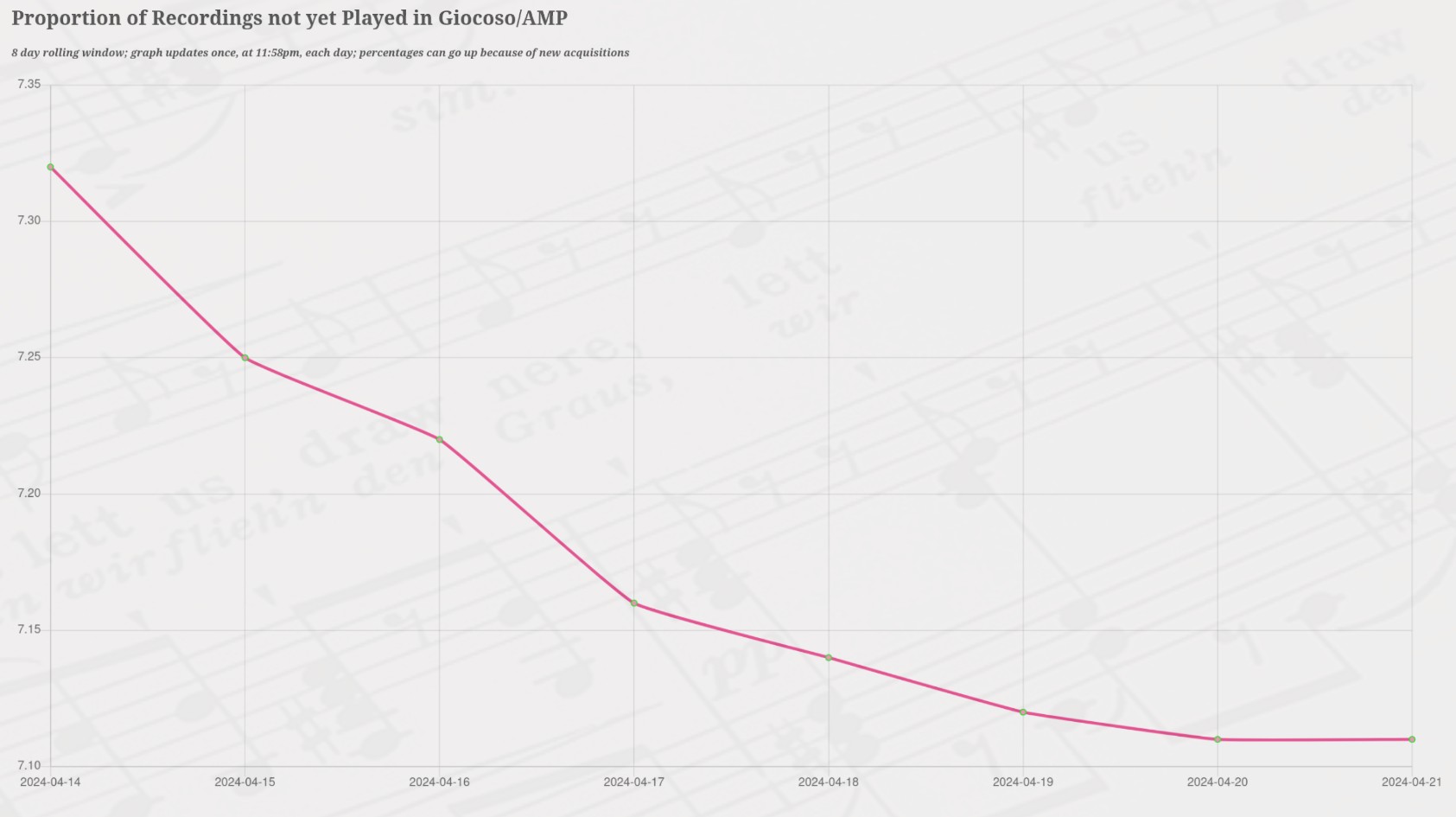
The graph at the left tells a tale! The context for that tale is that since June 3rd 2021, I've been using Giocoso to play (almost exclusively) only those recordings which have not previously been recorded as having been played, in an attempt to ensure that by the time I come to kick the bucket, I can say, hand-on-heart, that I've listened to every recording I ever bought. On the one hand, the tale is of good news: the graph shows that only 7.1% of my entire collection has not yet been played by Giocoso. So, I've played around 93% of it, which is pretty good going.
It's even better going when you consider that for much of the time since June 2021, I've had time restrictions on my plays: in other words, I've told Giocoso 'play unplayed recordings that last less than 20 minutes' or something similar. As a result, I haven't listened to Wagner's Ring cycle with Giocoso, but I know for certain I've played those recordings multiple, multiple times in the years before 2021. Which is to say: even the 7.1% I haven't 'officially' played contains substantial chunks of recorded music which I know I've played using different tools... so the amount of my collection which is truly unplayed is significantly less than 7%. [...]